
Giá trị bất thường của mẫu số liệu là gì? Đó là câu hỏi mà nhiều nhà phân tích dữ liệu, từ sinh viên đến chuyên gia, đều quan tâm. Tại merakicenter.edu.vn, chúng tôi tin rằng việc hiểu rõ và xử lý hiệu quả các giá trị ngoại lai này là chìa khóa để có được những phân tích chính xác và đáng tin cậy. Bài viết này từ merakicenter.edu.vn sẽ giúp bạn nắm vững khái niệm, nhận diện và xử lý chúng một cách hiệu quả nhất.
1. Giá Trị Bất Thường Của Mẫu Số Liệu Là Gì? Định Nghĩa & Tầm Quan Trọng
Giá trị bất thường, hay còn gọi là điểm ngoại lệ (outlier), là những điểm dữ liệu trong một tập dữ liệu mà giá trị của chúng khác biệt đáng kể so với phần lớn các điểm dữ liệu còn lại. Theo một nghiên cứu của Barnett và Lewis (1994) trong cuốn sách “Outliers in Statistical Data”, giá trị bất thường có thể xuất hiện do nhiều nguyên nhân khác nhau, từ lỗi đo lường đến những hiện tượng hiếm gặp nhưng có thật.
Tầm quan trọng của việc xử lý giá trị bất thường nằm ở chỗ chúng có thể gây ảnh hưởng lớn đến kết quả phân tích dữ liệu. Chúng có thể làm sai lệch các thống kê mô tả như giá trị trung bình và độ lệch chuẩn, dẫn đến những kết luận không chính xác. Ví dụ, một vài giá trị quá cao trong tập dữ liệu về thu nhập có thể làm tăng đáng kể giá trị trung bình, khiến bức tranh về tình hình tài chính của một nhóm người trở nên méo mó.
- Tác động tiêu cực đến mô hình: Trong các mô hình học máy, giá trị bất thường có thể làm giảm độ chính xác dự đoán và gây ra tình trạng overfitting (mô hình quá khớp với dữ liệu huấn luyện, dẫn đến khả năng khái quát hóa kém).
- Ảnh hưởng đến kiểm định giả thuyết: Trong thống kê suy luận, giá trị bất thường có thể làm thay đổi kết quả kiểm định giả thuyết, dẫn đến những quyết định sai lầm.
2. Dấu Hiệu Nhận Biết Giá Trị Bất Thường: Các Phương Pháp Hiệu Quả
Nhận diện giá trị dị thường là bước quan trọng để đảm bảo chất lượng phân tích. Có nhiều phương pháp khác nhau để thực hiện việc này, tùy thuộc vào đặc điểm của dữ liệu và mục tiêu phân tích.
- Phương pháp trực quan:
- Biểu đồ hộp (Box plot): Biểu đồ hộp hiển thị phân vị của dữ liệu, giúp dễ dàng nhận biết các điểm nằm ngoài “râu” của biểu đồ (thường được xác định là 1.5 lần IQR – khoảng tứ phân vị).

- Biểu đồ phân tán (Scatter plot): Biểu đồ phân tán hữu ích khi xem xét mối quan hệ giữa hai biến. Các điểm nằm xa so với cụm dữ liệu chính có thể là giá trị bất thường.

- Histogram: Giúp hình dung phân phối của dữ liệu, các giá trị nằm xa so với phần lớn dữ liệu có thể là ngoại lệ thống kê.

- Biểu đồ hộp (Box plot): Biểu đồ hộp hiển thị phân vị của dữ liệu, giúp dễ dàng nhận biết các điểm nằm ngoài “râu” của biểu đồ (thường được xác định là 1.5 lần IQR – khoảng tứ phân vị).
- Phương pháp thống kê:
- Z-score: Z-score đo lường số độ lệch chuẩn mà một điểm dữ liệu cách xa giá trị trung bình. Các điểm có Z-score lớn hơn một ngưỡng nhất định (thường là 2 hoặc 3) có thể được coi là giá trị bất thường. Công thức tính Z-score:
Z = (X - μ) / σTrong đó:
Xlà giá trị dữ liệuμlà giá trị trung bình của mẫuσlà độ lệch chuẩn của mẫu
- IQR (Interquartile Range): IQR là khoảng cách giữa phân vị thứ nhất (Q1) và phân vị thứ ba (Q3). Các điểm nằm ngoài khoảng
[Q1 - 1.5*IQR, Q3 + 1.5*IQR]thường được coi là giá trị bất thường. - Phương pháp Grubbs: Kiểm định Grubbs là một kiểm định thống kê được sử dụng để phát hiện một giá trị bất thường duy nhất trong một tập dữ liệu tuân theo phân phối chuẩn.
- Z-score: Z-score đo lường số độ lệch chuẩn mà một điểm dữ liệu cách xa giá trị trung bình. Các điểm có Z-score lớn hơn một ngưỡng nhất định (thường là 2 hoặc 3) có thể được coi là giá trị bất thường. Công thức tính Z-score:
- Sử dụng các thuật toán Machine Learning:
- Isolation Forest: Thuật toán này xây dựng các cây quyết định để phân tách các điểm dữ liệu. Các điểm cần ít bước phân tách hơn thường là giá trị bất thường.
- Local Outlier Factor (LOF): LOF tính toán mật độ cục bộ của mỗi điểm dữ liệu so với các điểm lân cận. Các điểm có mật độ thấp hơn đáng kể so với các điểm lân cận được coi là giá trị bất thường.
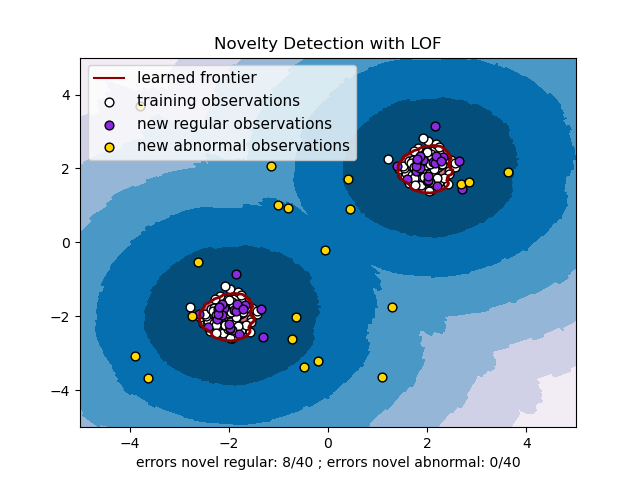
3. Nguyên Nhân Gây Ra Giá Trị Bất Thường: Hiểu Rõ Để Phòng Tránh
Việc xác định nguyên nhân gây ra giá trị bất thường có thể giúp chúng ta quyết định cách xử lý chúng một cách phù hợp. Có nhiều nguyên nhân khác nhau, bao gồm:
- Lỗi đo lường: Đây là nguyên nhân phổ biến nhất. Lỗi có thể xảy ra do thiết bị đo không chính xác, sai sót trong quá trình nhập liệu hoặc lỗi trong quá trình thu thập dữ liệu.
- Lỗi nhập liệu: Khi nhập dữ liệu thủ công, rất dễ xảy ra sai sót, chẳng hạn như nhập sai số hoặc đơn vị đo.
- Biến đổi dữ liệu: Trong quá trình biến đổi dữ liệu, chẳng hạn như chuyển đổi đơn vị đo hoặc tính toán các chỉ số mới, có thể xảy ra lỗi dẫn đến giá trị bất thường.
- Sự kiện hiếm gặp: Đôi khi, giá trị bất thường là kết quả của những sự kiện hiếm gặp nhưng có thật. Ví dụ, một đợt nắng nóng kỷ lục có thể dẫn đến những giá trị nhiệt độ cao bất thường.
- Do bản chất của dữ liệu: Một số tập dữ liệu có thể chứa các giá trị bất thường do bản chất của hiện tượng được nghiên cứu. Ví dụ, trong một tập dữ liệu về thu nhập, có thể có một số người có thu nhập rất cao so với phần còn lại.
4. Cách Xử Lý Giá Trị Bất Thường: Giải Pháp Cho Từng Trường Hợp
Sau khi nhận diện và xác định nguyên nhân gây ra giá trị bất thường, chúng ta cần quyết định cách xử lý chúng. Có một số phương pháp phổ biến, bao gồm:
| Phương Pháp | Mô Tả | Ưu Điểm | Nhược Điểm |
|---|---|---|---|
| Loại bỏ | Loại bỏ hoàn toàn các giá trị bất thường khỏi tập dữ liệu. | Đơn giản, dễ thực hiện. | Có thể làm mất thông tin quan trọng, đặc biệt nếu giá trị bất thường là kết quả của một sự kiện hiếm gặp. |
| Thay thế | Thay thế giá trị bất thường bằng một giá trị khác, chẳng hạn như giá trị trung bình, giá trị trung vị hoặc một giá trị được dự đoán từ mô hình. | Giữ lại kích thước mẫu ban đầu, giảm thiểu ảnh hưởng đến các thống kê mô tả. | Có thể làm sai lệch phân phối của dữ liệu nếu giá trị thay thế không phù hợp. |
| Winsorizing | Thay thế các giá trị cực đoan bằng các giá trị ít cực đoan hơn, chẳng hạn như phân vị thứ 5 và thứ 95. | Giảm thiểu ảnh hưởng của giá trị bất thường mà không loại bỏ chúng hoàn toàn. | Có thể làm thay đổi phân phối của dữ liệu. |
| Biến đổi dữ liệu | Áp dụng các phép biến đổi toán học để làm giảm ảnh hưởng của giá trị bất thường. Ví dụ, biến đổi logarit có thể làm giảm sự khác biệt giữa các giá trị lớn và nhỏ. | Có thể làm cho dữ liệu tuân theo phân phối chuẩn hơn, cải thiện hiệu suất của các mô hình thống kê. | Khó giải thích kết quả sau khi biến đổi. |
Theo một nghiên cứu của Osborne và Overbay (2004) đăng trên Practical Assessment, Research & Evaluation, việc lựa chọn phương pháp xử lý giá trị bất thường phù hợp phụ thuộc vào nhiều yếu tố, bao gồm nguyên nhân gây ra giá trị bất thường, đặc điểm của dữ liệu và mục tiêu phân tích.
Ví dụ minh họa:
Giả sử chúng ta có một tập dữ liệu về chiều cao của học sinh trong một lớp học. Hầu hết học sinh có chiều cao từ 150cm đến 180cm, nhưng có một học sinh cao 200cm. Giá trị này có thể là giá trị bất thường.
- Nếu giá trị này là do lỗi đo lường, chúng ta có thể loại bỏ hoặc thay thế nó bằng một giá trị hợp lý hơn (ví dụ: chiều cao trung bình của các học sinh khác).
- Nếu giá trị này là thật, chúng ta có thể giữ lại nó, nhưng cần lưu ý đến ảnh hưởng của nó đến kết quả phân tích.
5. Ảnh Hưởng Của Giá Trị Bất Thường Đến Phân Tích Dữ Liệu & Cách Giảm Thiểu Tác Động
Như đã đề cập, giá trị bất thường có thể gây ra nhiều vấn đề trong phân tích dữ liệu. Để giảm thiểu tác động tiêu cực của chúng, chúng ta cần:
- Nhận diện và xử lý giá trị bất thường một cách cẩn thận.
- Sử dụng các phương pháp phân tích mạnh mẽ (robust statistics) ít bị ảnh hưởng bởi giá trị bất thường. Ví dụ, thay vì sử dụng giá trị trung bình, chúng ta có thể sử dụng giá trị trung vị.
- Thực hiện phân tích độ nhạy để đánh giá ảnh hưởng của giá trị bất thường đến kết quả. Phân tích độ nhạy là quá trình thay đổi các giả định hoặc tham số đầu vào để xem kết quả phân tích có thay đổi đáng kể hay không.
6. Nâng Cao Kỹ Năng Phân Tích Dữ Liệu Với Merakicenter.edu.vn
Tại merakicenter.edu.vn, chúng tôi tin rằng việc nắm vững kiến thức về giá trị bất thường và các phương pháp xử lý chúng là một phần quan trọng của kỹ năng phân tích dữ liệu. Hy vọng bài viết này đã cung cấp cho bạn những thông tin hữu ích để áp dụng vào công việc và học tập. Đừng ngần ngại chia sẻ bài viết nếu bạn thấy nó hữu ích và tiếp tục khám phá thêm nhiều kiến thức thú vị khác trên merakicenter.edu.vn.
Nhận diện outlier, loại bỏ dữ liệu nhiễu, kiểm soát dữ liệu sai lệch.
Nội dung được phát triển bởi đội ngũ Meraki Center với mục đích chia sẻ và tăng trải nghiệm khách hàng. Mọi ý kiến đóng góp xin vui lòng liên hệ tổng đài chăm sóc: 1900 0000 hoặc email: [email protected]